Concepto
El modelo de variable dependiente binaria es un tipo de modelo que se utiliza para explicar fenómenos en los cuales la variable de relevancia es dicotómica o binaria, es decir, solo puede tomar dos valores. Hay multitud de ejemplos en el mundo económico y financiero sobre este tipo de decisiones: comprar o no una vivienda, entrar o no al mercado de trabajo, realizar o no una ampliación de capital,... Habitualmente, todas estas decisiones dependen de otras variables que permiten explicar sus determinantes; así, por ejemplo, la decisión de comprar o no una vivienda dependerá de la renta individual, del precio de los alquileres, del tipo de contrato laboral, etc.
Especificación de modelos de variable dependiente binaria
Los modelos con variable dependiente limitada son un caso particular de regresiones donde se quiere explicar la probabilidad de que se dé un fenómeno binario. Es decir, la variable a explicar Yi, solo puede tomar los valores 0 (si no se da el fenómeno) y 1 (si se da el fenómeno). Si, como es habitual, se supone que la probabilidad puede explicarse por otras variables xi el modelo, entonces, vendrá dado por:
Pr (Yi = 1) = F(β0 + β1x1,i + β2x2,i + ... + βkxk,i, o bien, Pr (Yi = 1) = F(BTx) donde la función F(.) representa la función de distribución de una variable aleatoria. Esta función de distribución representa la probabilidad acumulada de la variable aleatoria hasta el punto BTx y, habitualmente, si esta probabilidad es mayor que un determinado umbral (por ejemplo: 0.5), se considera que el individuo está más cerca de tomar la decisión dada por Yi=1 que de no tomarla (en cuyo caso Yi=0).
En general, las funciones F(.) elegidas para completar la especificación del modelo son la logística, denotada por 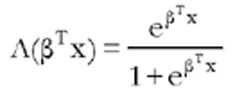 , en cuyo caso se obtiene el modelo Logit, y la normal, denotada por Ф(βTx), en cuyo caso se obtiene el modelo Probit. La función de distribución logística es similar a la normal en los valores centrales de la distribución, sin embargo, para valores extremos (probabilidades próximas a cero o uno), la distribución logística tiene mayor probabilidad en las colas que la distribución normal.
, en cuyo caso se obtiene el modelo Logit, y la normal, denotada por Ф(βTx), en cuyo caso se obtiene el modelo Probit. La función de distribución logística es similar a la normal en los valores centrales de la distribución, sin embargo, para valores extremos (probabilidades próximas a cero o uno), la distribución logística tiene mayor probabilidad en las colas que la distribución normal.
En ambos casos, Logit y Probit, el modelo es no lineal y, dadas las observaciones de la variable Y y del vector x, hay que utilizar técnicas de estimación por máxima verosimilitud, junto con algoritmos de optimización numérica, para estimar los parámetros β del modelo.
Una cuestión muy importante a tener en cuenta es que en estos modelos, a diferencia de los modelos de regresión habituales, los coeficientes βi no representan el cambio proporcional en la probabilidad de tomar la decisión cuando la correspondiente variable xi cambia en una unidad, es decir, los efectos marginales. Para calcular dichos efectos en estos modelos hemos de tener en cuenta que:
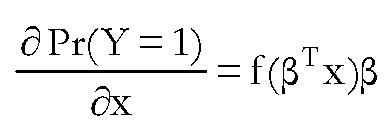
donde f(.) es la función de densidad de la distribución correspondiente. Así, operando en el modelo Logit, los efectos marginales vendrán dados por la expresión 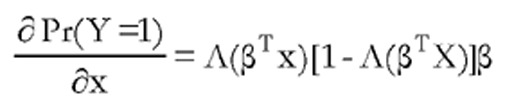 mientras que en el modelo Probit serán
mientras que en el modelo Probit serán 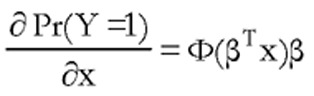 donde Ф(.) es la función de densidad de la normal estándar. Lo más importante es darse cuenta de que, en ambos casos, el efecto marginal (cambio en la probabilidad de Y=1 al cambiar la correspondiente xi) no es fijo sino que depende de los propios valores de xi. Así por ejemplo, en el modelo de compra de vivienda, al aumentar la renta el cambio en la probabilidad de compra será distinto según sea el nivel de renta del individuo y, también, según sean los valores del resto de variables explicativas de la compra. Esto es una diferencia importante respecto a los modelos lineales de regresión, donde los cambios vienen dados por los coeficientes βi y, como consecuencia, son los mismos para todos los individuos.
donde Ф(.) es la función de densidad de la normal estándar. Lo más importante es darse cuenta de que, en ambos casos, el efecto marginal (cambio en la probabilidad de Y=1 al cambiar la correspondiente xi) no es fijo sino que depende de los propios valores de xi. Así por ejemplo, en el modelo de compra de vivienda, al aumentar la renta el cambio en la probabilidad de compra será distinto según sea el nivel de renta del individuo y, también, según sean los valores del resto de variables explicativas de la compra. Esto es una diferencia importante respecto a los modelos lineales de regresión, donde los cambios vienen dados por los coeficientes βi y, como consecuencia, son los mismos para todos los individuos.
En algunas ocasiones, para obtener un efecto marginal representativo único, se evalúa la expresión anterior en los valores medios de las variables explicativas, es decir se evalúa 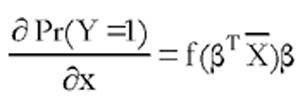 donde
donde 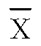 representa el vector de medias muestrales de las variables explicativas. Sin embargo, la representatividad de esta medida depende de la dispersión existente entre las variables x. Además, si alguna de estas variables explicativas es cualitativa (por ejemplo: sexo del individuo) no debería utilizarse la media muestral como valor central de esta variable.
representa el vector de medias muestrales de las variables explicativas. Sin embargo, la representatividad de esta medida depende de la dispersión existente entre las variables x. Además, si alguna de estas variables explicativas es cualitativa (por ejemplo: sexo del individuo) no debería utilizarse la media muestral como valor central de esta variable.
Estimación de modelos de variable dependiente binaria
Como hemos comentado anteriormente, la estimación de estos modelos requiere la utilización de técnicas de máxima verosimilitud que utilizarán la función de distribución supuesta para la variable Y (logística en el modelo Logit y normal en el Probit). Si se dispone de una muestra de observaciones independientes de la variable dependiente y las independientes, la función de verosimilitud vendrá dada por:
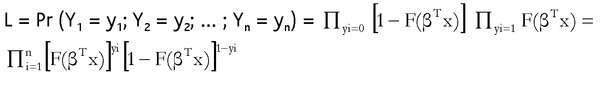
Tomando logaritmos (generalmente se maximiza el logaritmo de la función de verosimilitud en lugar de la verosimilitud propiamente dicha) se obtiene:
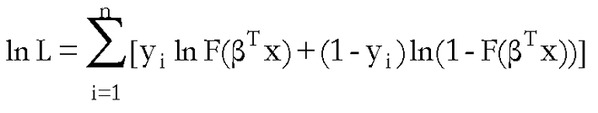
Como es habitual, la función F(.) será la función de distribución logística para el modelo Logit y normal para el modelo Probit.
Para maximizar esta función hay que calcular las condiciones de primer orden, dadas por 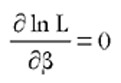 . Estas condiciones permiten obtener un número de ecuaciones igual al número de parámetros del vector β aunque, como estas ecuaciones son no lineales, se han de resolver mediante técnicas de optimización numérica lo cual permite obtener el vector de estimaciones
. Estas condiciones permiten obtener un número de ecuaciones igual al número de parámetros del vector β aunque, como estas ecuaciones son no lineales, se han de resolver mediante técnicas de optimización numérica lo cual permite obtener el vector de estimaciones 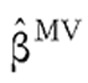 . Con este vector de estimaciones se pueden obtener los efectos marginales como se explicó en el apartado anterior.
. Con este vector de estimaciones se pueden obtener los efectos marginales como se explicó en el apartado anterior.
Una vez obtenidas las estimaciones máximo verosímiles, es posible obtener desviaciones típicas estimadas utilizando la matriz de derivadas segundas (o matriz hessiana) de la función de verosimilitud. En realidad, una estimación de las varianzas de los estimadores viene dada por la inversa de esta matriz (denominada matriz de información), es decir: 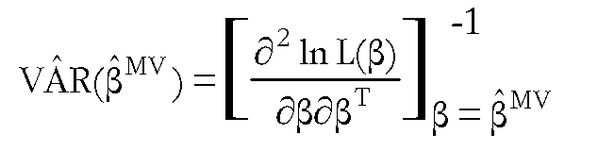
Además de obtener la matriz de varianzas de los coeficientes estimados, el método de máxima verosimilitud permite realizar contrastes sobre los coeficientes β utilizando tres tipos de test: ratio de verosimilititudes, multiplicadores de Lagrange y test de Wald. El ratio de verosimilitudes es un contraste basado en la evaluación del logaritmo de la función de verosimilitud obtenido en el modelo restringido (en el que se impone el valor de β que queremos contrastar) frente al modelo no restringido (el cual viene dado por el logaritmo de la verosimilitud evaluado en ). El test de multiplicadores de Lagrange tiene la ventaja de que solo necesita la evaluación de la función de verosimilitud en el modelo restringido, mientras que el test de Wald solo utiliza la evaluación en el modelo no restringido. Si la muestra es suficientemente grande los resultados con los tres tests serán similares. Afortunadamente, la gran mayoría del software econométrico y estadístico estándar incluye opciones de estimación y contraste de modelos Logit y Probit sin necesidad de tener conocimientos de programación específicos.
A modo de ejemplo, se expone un caso empírico, extraído del libro Introducción a la Econometría de Wooldridge, para explicar la participación de mujeres casadas en el mercado laboral (la base de datos incluye 753 observaciones). Las estimaciones por máxima verosimilitud de los modelos Logit y Probit fueron:
| Var. Indep. | Logit | Probit |
| Renta Fam. | - 0.021 (0.008) | - 0.012 (0.005) |
| educ. | 0.221 (0.043) | 0.131 (0.025) |
| Exper. | 0.206 (0.032) | 0.123 (0.019) |
| Exper2 | - 0.0032 (0.0010) | - 0.0019 (0.0006) |
| Edad | - 0.088 (0.015) | - 0.053 (0.008) |
| Niños Menores 6 años | - 1.443 (0.204) | - 0.868 (0.119) |
| Niños Entre 6-18 años | 0.060 (0.075) | 0.036 (0.043) |
| Contante (b0) | 0.425 (0.860) | 0.270 (0.509) |
| Porc. Clasificac. Corr. | 73.6% | 73.4% |
| Log. Verosim. | - 401.77 | - 401.30 |
| Pseudo R2 | 0.220 | 0.221 |
Los valores entre paréntesis representan desviaciones típicas estimadas.
Todos los signos de los coeficientes son los esperados y los estadísticos t (resultantes de dividir las estimaciones entre sus desviaciones típicas) son significativos. Con las estimaciones obtenidas ambos modelos resultan similares. Una medida de la bondad del ajuste obtenido es el porcentaje de observaciones clasificadas correctamente (asignando con valor 1 aquellas observaciones cuya probabilidad estimada sea mayor de 0.5). En ambos casos, este porcentaje ronda el 73.5 %. Por otro lado, se puede definir una medida similar al coeficiente de determinación (R2) específica para este tipo de modelos. En ambos casos esta medida del poder explicativo de las variables independiente sobre la probabilidad de entrar en el mercado laboral (que oscila entre 0 para el caso peor y 1 para un ajuste perfecto) está alrededor de 0.22.
Respecto a los efectos marginales si, por ejemplo, se suponen valores de renta=20.13, educ=12.3, exper=10.6, edad=42.5 y niños entre 6 a 18 años=1 entonces si el número de niños menores de 6 años pasa de valer 0 a valer 1, la probabilidad de participar en el mercado de trabajo para una mujer casada disminuye en 0.334 para el modelo Logit y disminuye en 0.347 para un modelo Probit (ambos son similares). Por supuesto, estos efectos marginales cambiarían si cambian los valores de las variables, por ejemplo, si el número de niños menores de 6 años pasara de 1 a 2 (manteniéndose constantes el resto de variables) la disminución sería de 0.256 para el modelo Logit.
Funciones índice
En algunas ocasiones los modelos Logit y Probit pueden recibir una interpretación a partir de una variable Y* no observable continua, la cual es una función lineal de las variables explicativas. Esta variable subyacente continua Y* puede interpretarse como un índice de utilidad del individuo y la relación con la variable observada es 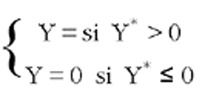
El modelo de regresión de la utilidad aleatoria no observable vendría dado por:
Y* = βTx + u
En este caso, la probabilidad de Y=1 podría expresarse como:
Pr (Y = 1) = Pr (Y* > 0) = Pr (βTx + u > 0) = Pr (u > - βTx) = Pr (u < βTx) = F(βTx)
donde se ha supuesto que la función de distribución F(.) es simétrica (como es el caso de la logística y la normal). A este modelo se le denomina modelo estructural para la probabilidad.
Extensiones de modelos de variable dependiente cualitativa
En algunas ocasiones, la variable dependiente no es dicotómica, sino multicotómica. Un ejemplo sencillo puede ser un modelo para elegir medio de transporte (coche, tren o autobús) en función de características individuales. En estos casos no es posible aplicar los modelos Logit y Probit binomiales anteriores aunque hay una extensión directa bajo el supuesto de que la distribución de la variable dependiente es multinomial (Logit multinomiales). Por otro lado, hay otros casos en que la variable dependiente es de carácter ordinal. Por ejemplo, imaginemos que se quiere modelizar el grado de aceptación de un producto y las alternativas que se establecen son: malo, aceptable, bueno o muy bueno. Como es obvio, existe un orden establecido en los valores de la variable (aunque no son cuantitativos). Este modelo puede estudiarse mediante una extensión de los modelos de utilidad aleatoria vistos en el apartado anterior, donde el cambio de los valores de la variable dependiente (por ejemplo: de bueno a muy bueno) se produce cuando el índice no observable Y* supera un determinado umbral que también habrá que estimar como un parámetro más del modelo. Para estimar este tipo de modelos se suele suponer una distribución normal y se les denomina Probit Ordered.
Recuerde que...
- • Los modelos con variable dependiente limitada son un caso particular de regresiones donde se quiere explicar la probabilidad de que se dé un fenómeno binario.
- • En general, las funciones elegidas para completar la especificación del modelo son la logística, en cuyo caso se obtiene el modelo Logit, y la normal, en cuyo caso se obtiene el modelo Probit.
- • En algunas ocasiones, la variable dependiente no es dicotómica, sino multicotómica.
- • El test de multiplicadores de Lagrange tiene la ventaja de que solo necesita la evaluación de la función de verosimilitud en el modelo restringido, mientras que el test de Wald solo utiliza la evaluación en el modelo no restringido.
- • La gran mayoría del software econométrico y estadístico estándar incluye opciones de estimación y contraste de modelos Logit y Probit sin necesidad de tener conocimientos de programación específicos.