Concepto
La estadística robusta trata de la aplicación de métodos estadísticos que no se vean afectados por la existencia de valores atípicos en la muestra.
Introducción
En el trabajo estadístico es habitual encontrarse con observaciones que, de alguna manera, parecen proceder de alguna distribución distinta al resto. A modo de ejemplo, imaginemos que se dispone de la siguiente muestra de la renta mensual en euros para individuos de una determinada población:
X= (1500; 2400; 1900; 2600; 35000)
Claramente, la última observación corresponde a un outlier o valor atípico y esta observación hace que las estimaciones habituales se vean muy afectadas por ese valor. Por ejemplo, la media muestral, dada por 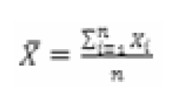 , toma un valor de 8.680 euros para esta muestra, lo cual está claramente encima del valor medio de la renta de toda la población. Sin embargo, si no tuviéramos en cuenta la última observación, el valor de la media muestral sería de 2.100 euros lo cual resulta más acorde con la realidad. Por supuesto, no solo la media resulta afectada, también la estimación de la desviación típica está seriamente distorsionada por la existencia de estas anomalías. Concretamente la cuasi-desviación típica muestral (estimador insesgado de la desviación típica poblacional), dada por
, toma un valor de 8.680 euros para esta muestra, lo cual está claramente encima del valor medio de la renta de toda la población. Sin embargo, si no tuviéramos en cuenta la última observación, el valor de la media muestral sería de 2.100 euros lo cual resulta más acorde con la realidad. Por supuesto, no solo la media resulta afectada, también la estimación de la desviación típica está seriamente distorsionada por la existencia de estas anomalías. Concretamente la cuasi-desviación típica muestral (estimador insesgado de la desviación típica poblacional), dada por 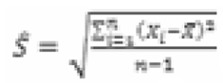 , tiene un valor de 14.719,61 para la muestra completa y de 496,66 si se elimina la última observación, lo cual da idea de la distorsión causada por la existencia de un único valor anómalo.
, tiene un valor de 14.719,61 para la muestra completa y de 496,66 si se elimina la última observación, lo cual da idea de la distorsión causada por la existencia de un único valor anómalo.
Por lo tanto, ante la existencia de valores atípicos que pueden distorsionar las estimaciones obtenidas caben dos opciones:
- 1. Detectar los valores atípicos, u outliers, y eliminarlos de la muestra para, posteriormente, aplicar los métodos tradicionales de estimación.
- 2. Diseñar métodos robustos de estimación que no se vean muy afectados por la existencia de estos outliers aunque, si la muestra no tuviera valores anómalos, las estimaciones fueran algo menos eficientes que las tradicionales.
Aunque el primer procedimiento pueda resultar atractivo, la realidad es que, en muchas ocasiones, es difícil detectar los outliers, especialmente si proceden de distribuciones con más de una variable. A modo de ejemplo, en el siguiente gráfico bidimensional se puede apreciar como hay un valor atípico aunque, sin embargo, si se analizan los valores de X e Y por separado (3,41 y 11,28 respectivamente) ninguno de ellos resulta atípico por sí solo (es la combinación de ambos la que es atípica).
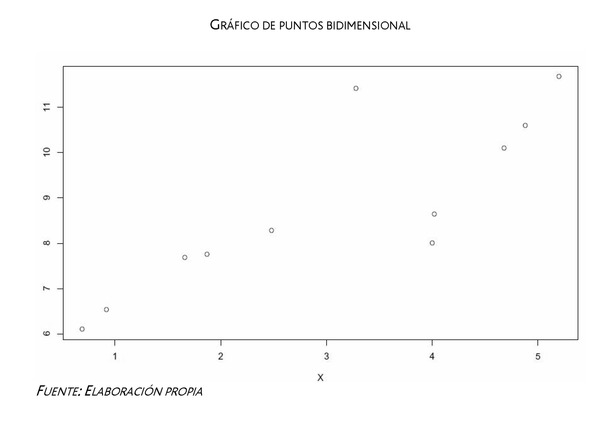
Debido a estas razones de dificultad y subjetividad en la detección de valores atípicos cada vez se está extendiendo más la segunda alternativa de aplicar métodos robustos en las estimaciones estadísticas.
Métodos robustos de estimación
Los métodos de la estadística robusta están diseñados para verse poco afectados cuando se producen anomalías en las muestras. Si, en el ejemplo anterior, para estimar la renta media usáramos la mediana muestral (definida como el valor central que deja el 50 % de la distribución a ambos lados) en lugar de la media muestral, el resultado obtenido hubiera sido de 2.400 para la muestra completa y de 2.150 (promedio entre 1.900 y 2.400) para la muestra sin la observación atípica. Como conclusión, la mediana muestral resulta mucho menos afectada que la media muestral por la existencia de valores atípicos. Como contrapartida, hay que señalar que, si las observaciones Xi procedieran de una distribución N(μ;σ2), la varianza de la mediana muestral sería un 57 % mayor que la de la media muestral siendo, por tanto, menos eficiente utilizar la mediana que la media cuando todos los datos muestrales proceden del modelo supuesto. Sin embargo, la función de influencia, definida como el grado en que se ve afectado un estimador por la existencia de un valor atípico, no está acotada para la media muestral (es decir, si el valor anómalo crece sin límite, lo mismo ocurriría para la media) y, por otro lado, está acotada para la mediana muestral.
Estimadores robustos de localización
Además de la mediana muestral, existen otros estimadores alternativos a la media que son robustos frente a la existencia de outliers. Entre ellos, quizá los más intuitivos son las α-medias recortadas, las cuales eliminan un porcentaje α de las observaciones muestrales en cada extremo. En nuestro ejemplo simple anterior, la 0.2-media sería la media una vez que eliminamos el 20 % de las observaciones en cada cola (en nuestro caso, una observación en cada extremo), es decir:  .
.
Una alternativa a recortar la muestra consiste en winsorizar la muestra. Una muestra α-winsorizada sustituye el porcentaje α de observaciones extremas en cada cola de la distribución con las observaciones más cercanas. En el ejemplo, la muestra winsorizada al 20 % vendría dada por X0.2-win=(1900;1900;2400;2600;2600)
A partir de aquí la estimación winsorizada de la media consiste, simplemente, en calcular la media muestral sobre dicha muestra winsorizada, en nuestro caso el valor vendrá dado por: 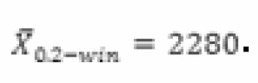 .
.
Como ya se ha comentado anteriormente, en general las estimaciones robustas (mediana, media recortada y media winsorizada) son menos eficientes que los estimadores clásicos, como la media muestral, cuando las observaciones muestrales proceden de distribuciones normales. Sin embargo, como hemos visto en el ejemplo, son mucho más robustos cuando hay valores anómalos (su función de influencia está acotada mientras que la de la media muestral no lo está). Para diseñar estimadores que sigan siendo robustos y, además, ganen eficiencia en el caso de distribuciones normales, se han propuesto los denominados M-estimadores que constituyen una familia de estimadores robustos basados en una generalización de los estimadores máximo-verosímiles. Aunque su cálculo resulta a veces complejo, en gran parte del software estadístico especializado se pueden obtener sin esfuerzo, especialmente el estimador de Huber lo cual está permitiendo su difusión en los análisis estadísticos habituales.
En general, un modo intuitivo de comprobar si la muestra puede contener outliers que distorsionen los resultados es calcular estimadores clásicos y robustos analizando las diferencias entre ellos. Si ambos tipos de estimadores difieren poco, probablemente no haya grandes anomalías en la muestra y los estimadores clásicos sean adecuados; en otro caso, puede ser más conveniente utilizar estimadores robustos.
Estimadores robustos de escala
Al igual que existen alternativas robustas a la media (el cual es un estimador de localización), también existen alternativas robustas a la desviación típica como estimador de escala. Entre las más habituales se encuentra la desviación absoluta mediana, definida como la mediana de las desviaciones en valor absoluto respecto a la mediana, es decir:
MAD = Mediana {|Хi - Mе|}ni = 1
En nuestro ejemplo anterior, la mediana muestral era 2.400 y las desviaciones en valor absoluto respecto a la mediana son: (900,500,0,200,32600). El MAD vendrá dado por la mediana de esas desviaciones absolutas, es decir, 500. En general, para comparar esta medida con la desviación típica, es necesario estandarizarla dividiendo por 0,6745 por lo cual se obtiene el valor del MAD estandarizado, o NMAD, el cual es una medida de dispersión comparable con la desviación típica, 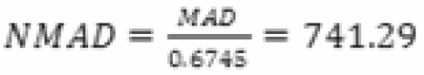 . Si se compara este valor con el de la cuasi-desviación típica muestral de la muestra original (14.719,61) puede comprobarse hasta qué punto hemos disminuido la influencia de un único valor anómalo (de hecho, la función de influencia del NMAD está acotada mientras que la de la cuasi-desviación típica muestral no lo está). Otro estimador de dispersión robusto es el rango intercuartílico definido como la distancia entre las cuales está el 50 % central de los valores muestrales, es decir RIQ = Percentil0,75 = Percentil0,25 = 2600 — 1900 = 700. Como ocurría en el caso anterior de estimadores de localización, los estimadores robustos de escala son menos eficientes que la cuasi-desviación típica muestral en el caso de observaciones procedentes de la normal aunque mucho más adecuados cuando hay outliers en la muestra. También existen alternativas robustas winsorizadas y recortadas en los parámetros de escala e, incluso, se pueden definir M-estimadores robustos también en este caso.
. Si se compara este valor con el de la cuasi-desviación típica muestral de la muestra original (14.719,61) puede comprobarse hasta qué punto hemos disminuido la influencia de un único valor anómalo (de hecho, la función de influencia del NMAD está acotada mientras que la de la cuasi-desviación típica muestral no lo está). Otro estimador de dispersión robusto es el rango intercuartílico definido como la distancia entre las cuales está el 50 % central de los valores muestrales, es decir RIQ = Percentil0,75 = Percentil0,25 = 2600 — 1900 = 700. Como ocurría en el caso anterior de estimadores de localización, los estimadores robustos de escala son menos eficientes que la cuasi-desviación típica muestral en el caso de observaciones procedentes de la normal aunque mucho más adecuados cuando hay outliers en la muestra. También existen alternativas robustas winsorizadas y recortadas en los parámetros de escala e, incluso, se pueden definir M-estimadores robustos también en este caso.
En general, conocer el comportamiento de los estimadores robustos en muestras pequeñas suele ser un problema complejo y, en muchas ocasiones, hay que recurrir a técnicas de remuestreo (bootstrap y jacknife).
Para acabar hay que señalar que, por supuesto, la estadística robusta se utiliza no solo para aminorar las influencias de los outliers en las estimaciones de parámetros de localización y escala, sino en prácticamente todos los ámbitos del análisis estadístico incluyendo regresión, análisis multivariante y series temporales.
Recuerde que...
- • Ante la existencia de valores atípicos que pueden distorsionar las estimaciones obtenidas caben dos opciones: 1. Detectar los valores atípicos u outliers y eliminarlos de la muestra para, posteriormente, aplicar los métodos tradicionales de estimación. 2. Diseñar métodos robustos de estimación que no se vean muy afectados por la existencia de estos outliers.
- • Las estimaciones robustas (mediana, media recortada y media winsorizada) son menos eficientes que los estimadores clásicos cuando las observaciones muestrales proceden de distribuciones normales.
- • Un modo intuitivo de comprobar si la muestra puede contener outliers que distorsionen los resultados es calcular estimadores clásicos y robustos analizando las diferencias entre ellos.
- • Si ambos tipos de estimadores difieren poco, probablemente no haya grandes anomalías en la muestra y los estimadores clásicos sean adecuados; en otro caso, puede ser más conveniente utilizar estimadores robustos.
- • Al igual que existen alternativas robustas a la media (el cual es un estimador de localización), también existen alternativas robustas a la desviación típica como estimador de escala..